Hello , I'm Berk Yilmaz.
Currently pursuing an M.S. in Electrical Engineering @ Columbia University, specializing in Data-Driven Analysis and Computation. Before Columbia, I completed a dual B.S. degree in Electrical Engineering from NJIT (Magna Cum Laude, GPA 3.82) and in Electronics and Communications Engineering from Istanbul Technical University, where I graduated first in my department (GPA 3.88).
My journey has been shaped by the idea that signal systems and hardware can harmonize with AI to create technology that’s not only powerful but also efficient and human-centered. At Columbia, I’ve led first-author research on knowledge distillation for Jetson Nano, Mixture-of-Experts router optimization, and energy-efficient CNN transformations, while also developing GPT-4-powered recommendation systems and real-time financial NLP tools. Earlier, as a research assistant at NJIT, I built NLP and computer vision systems in CARLA using Jetson AI, PyTorch, TensorFlow, and Keras, exploring how AI models interact with real-world data and embedded devices.
Across more than ten graduate-level projects, spanning Neural Networks, Reinforcement Learning, Embedded AI, and Big Data Analytics. I’ve grown increasingly passionate about the energy efficiency of intelligent systems. I believe the next breakthroughs in AI won’t just come from making models larger, but from making them smarter, leaner, and more sustainable, an idea that guides both my studies and my work.


Berk Yilmaz
AI Engineer
MSEE @ Columbia University, BSEE @ NJIT/ITU
Welcome to my portfolio , a collection of projects that reflect my curiosity, growth, and love for building meaningful technology.
Efficient Transformations in Deep Learning Convolutional Neural Networks
Berk Yilmaz, Columbia University
Dan Harvey, Columbia University
Prajit Dhuri, Columbia University
""" I want to start with this project because it aligns closely with my goals, creating AI systems that are not only intelligent, but also efficient, sustainable, and meaningful in the way they serve people. """
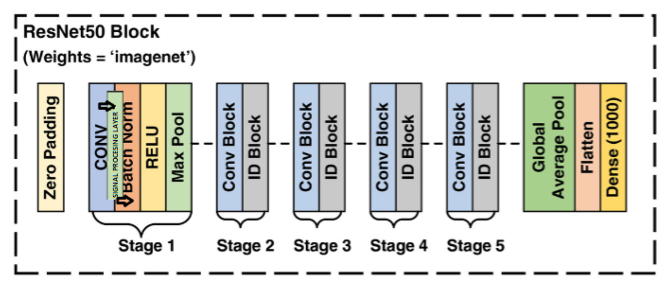
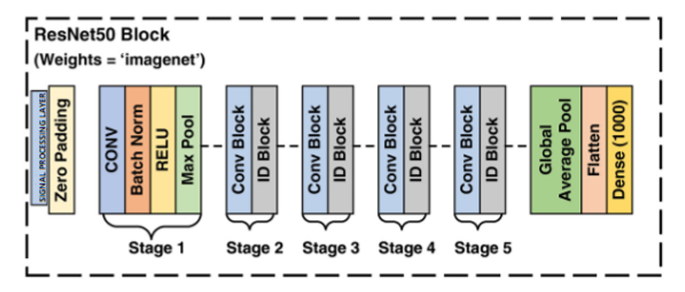
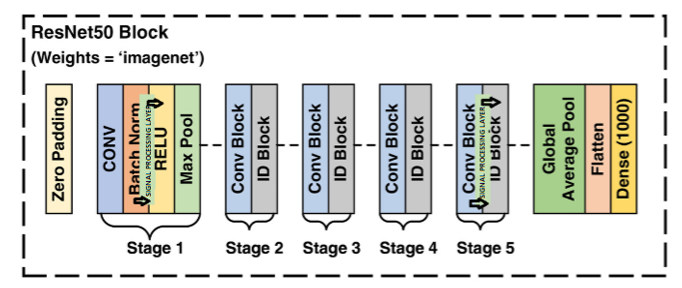
The core of my "Efficient Transformations in Deep Learning Convolutional Neural Networks" project was to investigate how signal processing transformations could enhance CNNs for image classification, striking a balance between computational efficiency, energy consumption, and accuracy. Working with Daniel Harvey and Prajit Dhuri at Columbia University, we modified the ResNet50 architecture and tested it on the CIFAR-100 dataset, which includes 100 classes and 60,000 low-resolution (32x32) images (50,000 for training and 10,000 for testing). The baseline ResNet50 achieved 66% test accuracy but consumed a hefty 25,606 kJ of energy. By integrating the Walsh-Hadamard Transform (WHT) into early layers, we improved accuracy to 74%, and extending it to both early and late layers boosted it to 79% while reducing energy use to just 39 kJ—a 99.8% reduction. We hypothesized that these transformations uncover hidden frequency-domain features that traditional CNNs often overlook, allowing us to lower dimensionality without compromising performance. My focus was on visual media, conceptualized as 2D grids with width, height, and RGB channels, where low frequencies represent tones and colors, and high frequencies capture edges and textures techniques familiar from Photoshop’s sharpening effects. Transformations like the Fast Fourier Transform (FFT) for spectral analysis, Discrete Cosine Transform (DCT) for compression, and WHT (with its orthogonal, scalable O(sqrt(N)) complexity) shift data into frequency domains, minimizing redundancy. Inspired by WHT’s historical use in NASA’s 1960s image compression for interplanetary probes, which outperformed linear methods, I saw its potential for modern efficiency. Our goal was to embed WHT, FFT, and DCT into ResNet50 for CIFAR-100 classification, experimenting with placements at the input, early layers, and a combination of early and late layers, then comparing results against a baseline. This approach diverged from prior studies limited to ResNet-18/34 or just two transforms, leveraging a deeper model and all three while tracking accuracy, energy, and compute metrics. I implemented each as a custom Keras layer. For FFT, I approximated the Discrete Fourier Transform (DFT) with O(N log N) complexity (versus DFT’s O(N²)), rooted in Fourier’s 1807 theory that any periodic signal is a sum of sines and cosines (X_k = sum x_n e^(-j2πkn/N)). For images in the spatial domain, I converted RGB (e.g., 232x232x3) to grayscale (232x232x1), applied a 2D FFT, and used magnitude to highlight broad structures and phase to preserve positions, employing high/low-pass filters for smoothing or edge enhancement, with code using tf.signal.fft2d and abs on complex64 data. The DCT (DCT-II variant) expressed data as cosine sums, ideal for compression standards like MPEG/H.263 (X_k = sum x_n cos(π(k)(n+0.5)/N)), and was orthonormal for stability. Since TensorFlow’s tf.signal.dct is 1D, I transposed 2D data (applying it along width, then height), verifying energy equivalence with Parseval’s Theorem. The WHT, building on Hadamard (1893) and Walsh (1923), used a recursive 2x2 matrix (H_n = [H_{n/2} H_{n/2}; H_{n/2} -H_{n/2}], H1=1), normalized by 1/sqrt(N), with O(N log N) complexity suited for powers-of-2 data. For 2D images, I transposed [B,H,W,C] to [B,C,H,W], flattened BC, applied the matrix along height and width, and reverted the shape, confirming reversibility with near-zero absolute differences. We started with a pre-trained ResNet50 on ImageNet, fine-tuning it on CIFAR-100 by upscaling 32x32 to 224x224. The training was two-phased: initially freezing weights, then unfreezing them, with added 2D average pooling, 0.5 dropout, a dense layer (100 units, softmax, L2=1e-4), Adam optimizer, and sparse categorical crossentropy loss. Model configurations included Transform after input, in early conv (conv2_block1), and in both early and late layers, showcasing my ability to innovate at the hardware-AI intersection for sustainable, efficient solutions.
Download the Efficient Transformations in Deep Learning Convolutional Neural Networks PDF File
The archiveX paper is avaliable : https://arxiv.org/abs/2506.16418
Also, you can access the PDF file by clicking.


PharMe : A Pharmaceutical Informed LLM
Keeping Healthcare Providers Up to Date with the Latest Treatments
Berk Yilmaz, Columbia University
Dan Harvey, Columbia University
Ishraw Khan, Columbia University

Watch us talk about our technology
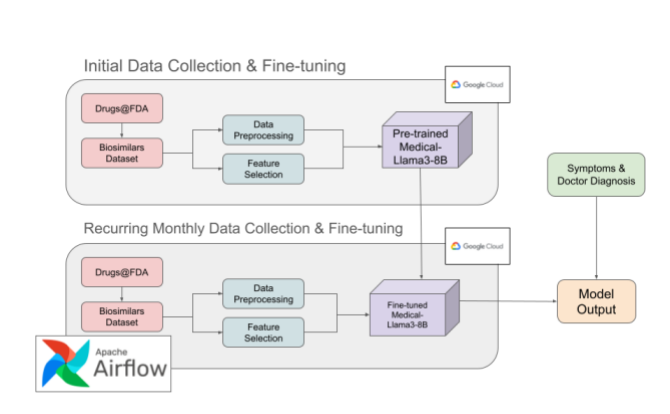
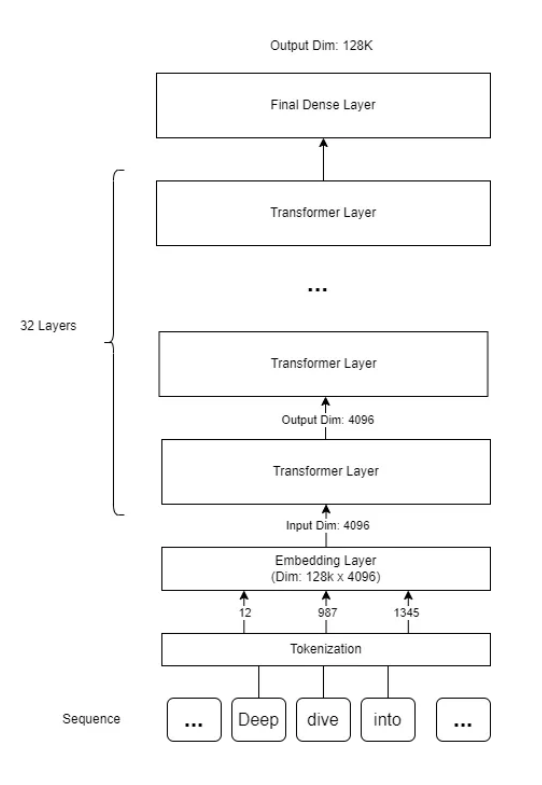
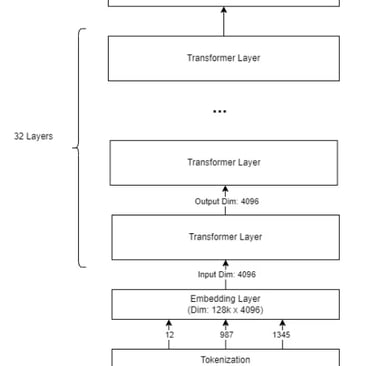
One of the standout projects in my portfolio is "PharMe: A Pharmaceutical Informed LLM – Keeping Healthcare Providers Up to Date with the Latest Treatments," a collaborative final project with Dan Harvey (Computer Science) and Ishraq Khan (Data Science) at Columbia University for EECS E6893 Big Data Analytics. As Teaching Assistant for this graduate course with 90+ MS/PhD students under Prof. Ching-Yung Lin—leading recitations on Hadoop, Apache Spark, and distributed systems while conducting code reviews, this work is particularly meaningful, showcasing big data's transformative role in healthcare through automated Apache Airflow workflows for processing dynamic datasets
We fine-tuned Medical Llama-3-8B (pre-trained on MIMIC-III's 40M+ rows of de-identified EHR data from 40K+ ICU patients, 2001-2012) using Drugs@FDA's Purple Book, incorporating 324 updates from 2024 (including 50 novel drugs and 18 biosimilars). An Airflow DAG automated monthly CSV pulls, parsing, and fine-tuning to ensure real-time currency. PharMe delivers context-aware recommendations for diagnoses, suggesting treatments, novel therapies, and cost-effective biosimilars/generics, achieving a perplexity of 17.4 (outperforming GPT-Neo's 21.7 and baselines like Bloom-3B/GPT-J-6B in accuracy/F1 on a 200-medication dataset).
Providers face FDA's rapid innovations, e.g., Steqeyma (biosimilar for Stelara in autoimmune conditions)—amid biased sales reps, delayed journals (2-3 month lag), and costly conferences. EHRs flag basics, but PharMe leverages big data for unbiased, efficient support, enhancing prescribing in private practices.
Related works include LEADER for EHR recommendations and GA-DRUG for genetic interactions, but PharMe uniquely focuses on biosimilars/generics with recurring updates, mitigating hallucinations via human oversight. Data handling, MIMIC-III for foundational knowledge; Purple Book CSVs (354x26 dataframe, NRU updates varying 17-79/month) preprocessed in Pandas. Methods included Airflow for collection/processing; 4-bit quantization, 50-epoch fine-tuning (0.72 loss); Tkinter/Flask interfaces.


You can access the PDF File : here
Cross-Architecture Knowledge Distillation (KD) for Retinal Fundus Image Anomaly Detection on NVIDIA Jetson Nano
Berk Yilmaz, Columbia University
Aniruddh Aiyengar, Columbia University
""" This work is particularly special to me as it embodies my passion for energy-efficient AI in healthcare"""
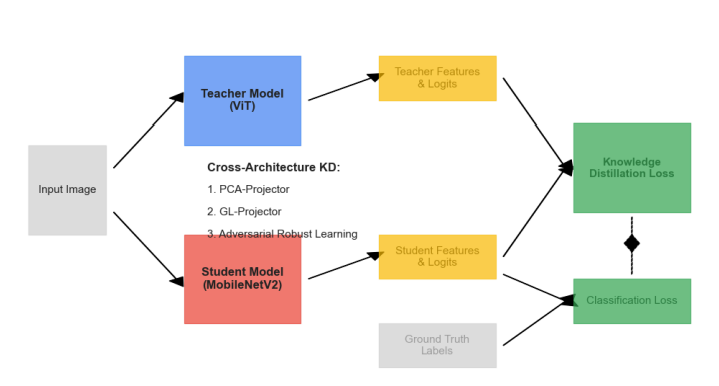
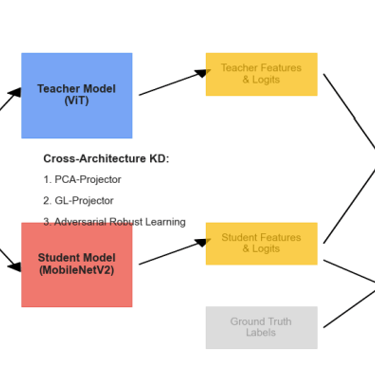
We developed a lightweight CNN student model that achieves 89% accuracy in classifying fundus images as Normal, Diabetic Retinopathy, Glaucoma, or Cataract, retaining 93% of a high-capacity ViT teacher's 92.87% performance while reducing parameters by 97.4% (from 85.8M to 2.2M) for edge deployment. We pre-trained the ViT teacher using I-JEPA self-supervised learning on unlabeled images, employing block-wise masking (60-75% ratio) to learn semantic features via latent space prediction, avoiding pixel-level reconstruction pitfalls. The objective minimized L(x; θ, φ, ψ) = ∑|h_ψ(f_θ(x_c), m) - g_φ(x_m)|^2 over masked regions, with EMA updates for stability. For distillation, we introduced a PCA projector to infuse transformer-like attention into the CNN via query/key/value convolutions and KL divergence loss, plus a GL projector for group-wise feature alignment using 1x1 convolutions and MSE loss. Multi-view robust training generated augmented views (crops, jitter) and added adversarial discrimination (3-layer MLP with BCE loss) to enhance generalization, combining losses as L_total = L_PCA + λ1 L_GL + λ2 L_adv + α L_CE.Implemented in PyTorch with timm/torchvision, we used a custom RetinalFundusDataset (6,727 images split 74/16/10%) with targeted augmentations to address imbalances (e.g., Normal 38.5%). Training over 50 epochs yielded strong metrics: precision/recall/F1 macro averages of 0.90/0.86/0.88. On Jetson Nano, the quantized model ran at 3.5 FPS with low power (2.6W inference), enabling real-time triage.
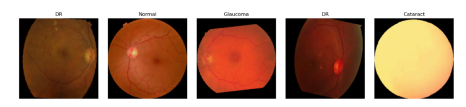
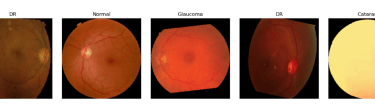
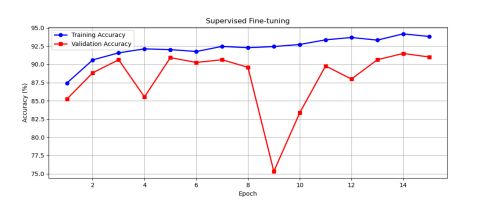
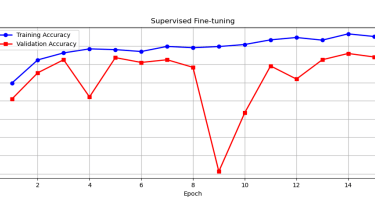
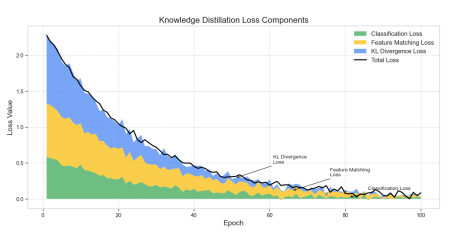
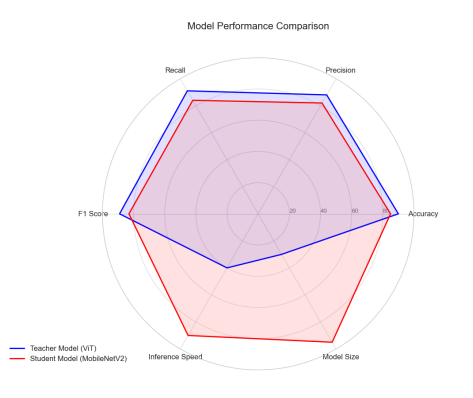
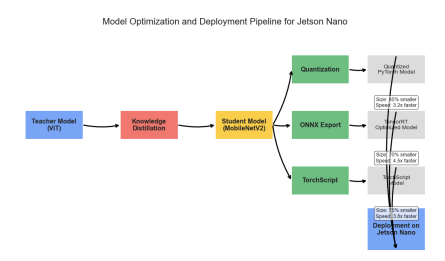
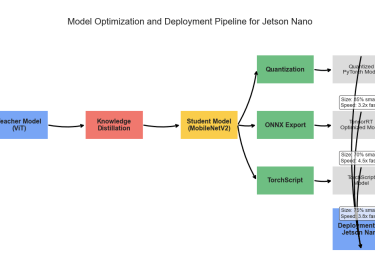
You can download the paper : here
Optimizing MoE Routers: Design, Implementation, and Evaluation in Transformer Models
Berk Yilmaz, Columbia University
Dan Harvey, Columbia University
George Weale, Columbia University
“Order and simplification are the first steps toward mastery of a subject.”
— Thomas Mann, The Magic Mountain (1924)
"Optimizing MoE Routers: Design, Implementation, and Evaluation in Transformer Models," is a collaborative effort with Dan Harvey (Computer Science) and George Weale (Computer Science) at Columbia University (arXiv:2506.16419v1, DBGW). MoE models scale LLMs by activating sparse experts per token, but routers often cause imbalance/reduced accuracy. We designed routers to capture complex token-expert relations: Linear (softmax(W·x+b)); Attention (scores(q,k)=q·k^T/√d_k·τ, softmax); MLP (h=σ(W1·x+b1), softmax(W2·h+b2)); Hybrid (linear+attention combo); Hash (parameter-free deterministic); MLP-Hadamard (MLP with Hadamard matrix for structured sparsity). Evaluated on BERT (GLUE tasks) and Qwen1.5-MoE (fine-tuned), focusing on trade-offs like speed vs. expressiveness. Contributions: Modular MoE layer for swappable routers, entropy/utilization metrics, and novel MLP-Hadamard for efficient sparsity. MoEs enable trillion-parameter models with low inference cost via conditional activation, but linear softmax routers limit feature capture, causing overload/underuse. Motivation: Optimize routing for better balance/specialization without overhead. Objectives: Implement/test variants, create evaluation framework (entropy H= -∑p_i log p_i, utilization U=1/n ∑I(∑p_i>0)), identify designs for scenarios like edge deployment. Built on Shazeer et al. [1] (sparse gating), Fedus et al. [2] (Switch Transformers with load balancing loss, top-1 routing), Roller et al. [3] (hash routing), Puigcerver et al. [4] (soft MoEs), and Mixtral [7] (top-k experts). Our novelty: Comparative analysis of six routers in standardized setup, including MLP-Hadamard hybrid. System includes Router Base (compute_router_probabilities method), MoE Layer (integrates any router, top-k selection, auxiliary balance loss L_bal= (1/n ∑f_i)^2 + (1/n ∑(f_i - 1/n)^2) where f_i=expert frequency), Evaluation Framework (PyTorch metrics for latency/entropy). Routers coded with inductive biases: Attention for global context, MLP for non-linearity, Hadamard for orthogonal projections (H_n recursive matrix). Used PyTorch/torchvision; BERT-base (110M params) with 8 experts/layer; Qwen1.5-MoE (quantized 4-bit). Training: GLUE for BERT (epochs=3, lr=2e-5), custom fine-tuning for Qwen. Hash: Deterministic token hashing; MLP-Hadamard: MLP output multiplied by normalized Hadamard for sparse patterns. On BERT: Attention router best accuracy (85% GLUE avg), MLP-Hadamard lowest entropy (balanced loads). Latency: Linear fastest (5ms/inference), Attention slowest (+20%). Expert utilization: Hash even but brittle; MLP-Hadamard 95% balanced. Qwen: Fine-tuned routers maintained 93% base perplexity, with MLP-Hadamard reducing imbalance by 40%. Visuals: Heatmaps showed structured routing in Hadamard variants. Linear/Hash suit speed-critical apps; Attention/MLP for accuracy. Limitations: Scalability to 100+ experts. Future: Dynamic k, integration with Grok-like models.
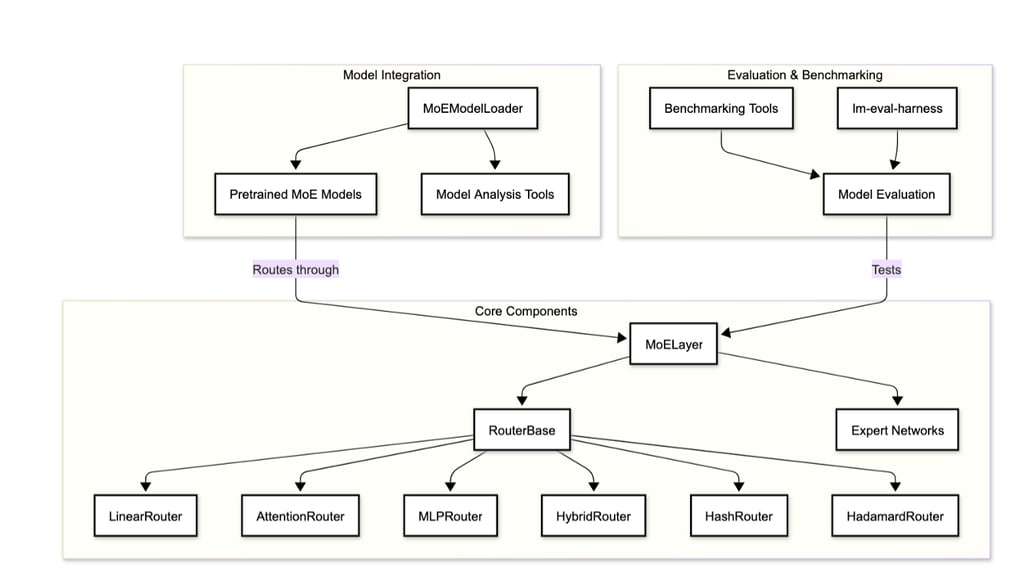
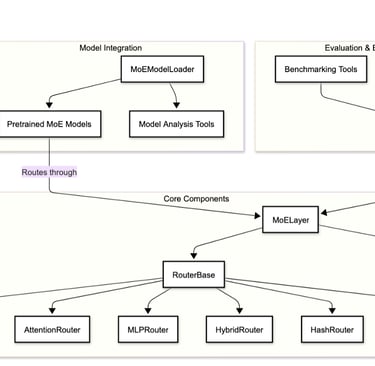
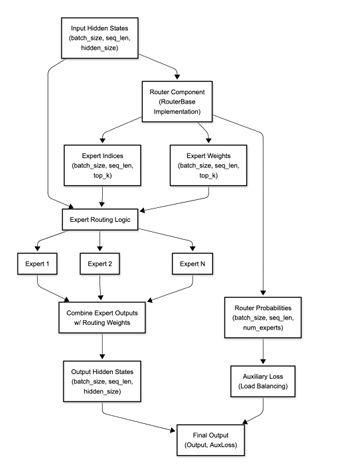
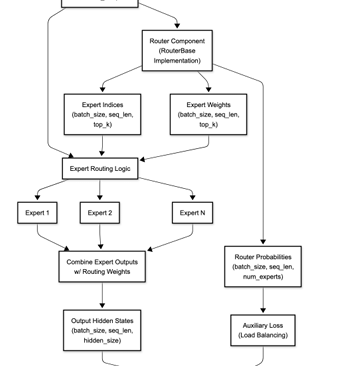
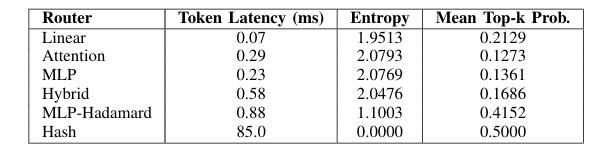
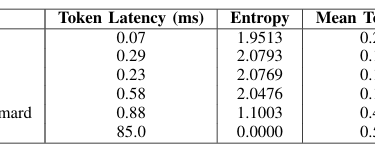
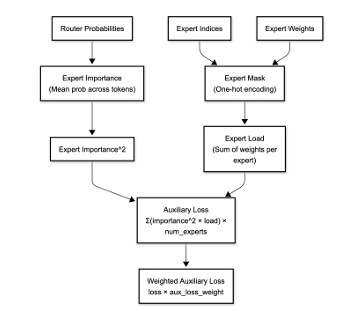
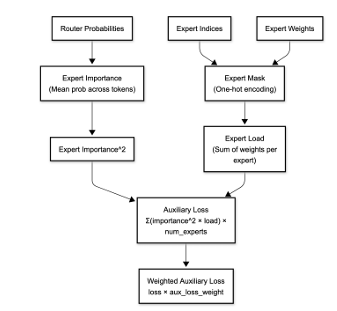
The archiveX paper is avaliable : https://arxiv.org/abs/2506.16419
Cross-Architecture Knowledge Distillation (KD) for Retinal Fundus Image Anomaly Detection on NVIDIA Jetson Nano
Berk Yilmaz, Columbia University
Aniruddh Aiyengar, Columbia University
""" This work is particularly special to me as it embodies my passion for energy-efficient AI in healthcare"""
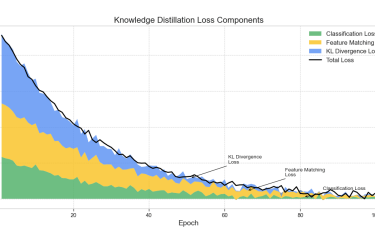
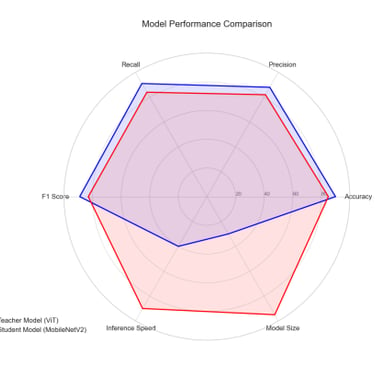
We developed a lightweight CNN student model that achieves 89% accuracy in classifying fundus images as Normal, Diabetic Retinopathy, Glaucoma, or Cataract, retaining 93% of a high-capacity ViT teacher's 92.87% performance while reducing parameters by 97.4% (from 85.8M to 2.2M) for edge deployment. We pre-trained the ViT teacher using I-JEPA self-supervised learning on unlabeled images, employing block-wise masking (60-75% ratio) to learn semantic features via latent space prediction, avoiding pixel-level reconstruction pitfalls. The objective minimized L(x; θ, φ, ψ) = ∑|h_ψ(f_θ(x_c), m) - g_φ(x_m)|^2 over masked regions, with EMA updates for stability. For distillation, we introduced a PCA projector to infuse transformer-like attention into the CNN via query/key/value convolutions and KL divergence loss, plus a GL projector for group-wise feature alignment using 1x1 convolutions and MSE loss. Multi-view robust training generated augmented views (crops, jitter) and added adversarial discrimination (3-layer MLP with BCE loss) to enhance generalization, combining losses as L_total = L_PCA + λ1 L_GL + λ2 L_adv + α L_CE.Implemented in PyTorch with timm/torchvision, we used a custom RetinalFundusDataset (6,727 images split 74/16/10%) with targeted augmentations to address imbalances (e.g., Normal 38.5%). Training over 50 epochs yielded strong metrics: precision/recall/F1 macro averages of 0.90/0.86/0.88. On Jetson Nano, the quantized model ran at 3.5 FPS with low power (2.6W inference), enabling real-time triage.
You can download the paper : here